Combination of Multivariate Standard Addition Technique and Deep Kernel Learning Model for Determining Multi-Ion in Hydroponic Nutrient Solution


Abstract
:1. Introduction
2. Materials and Methods
2.1. Experiment Preparation
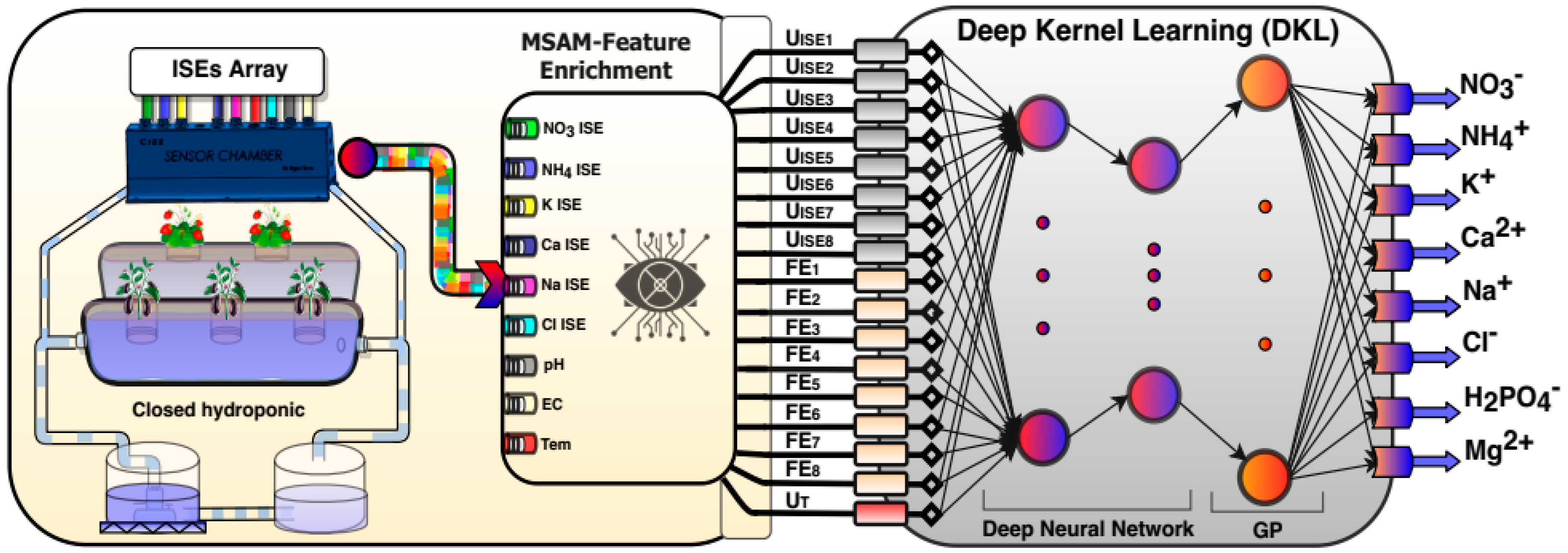
2.1.1. Sensor Array and Apparatus
2.1.2. Sampling Preparation
2.2. Development of Models for Determining Multi-Ion
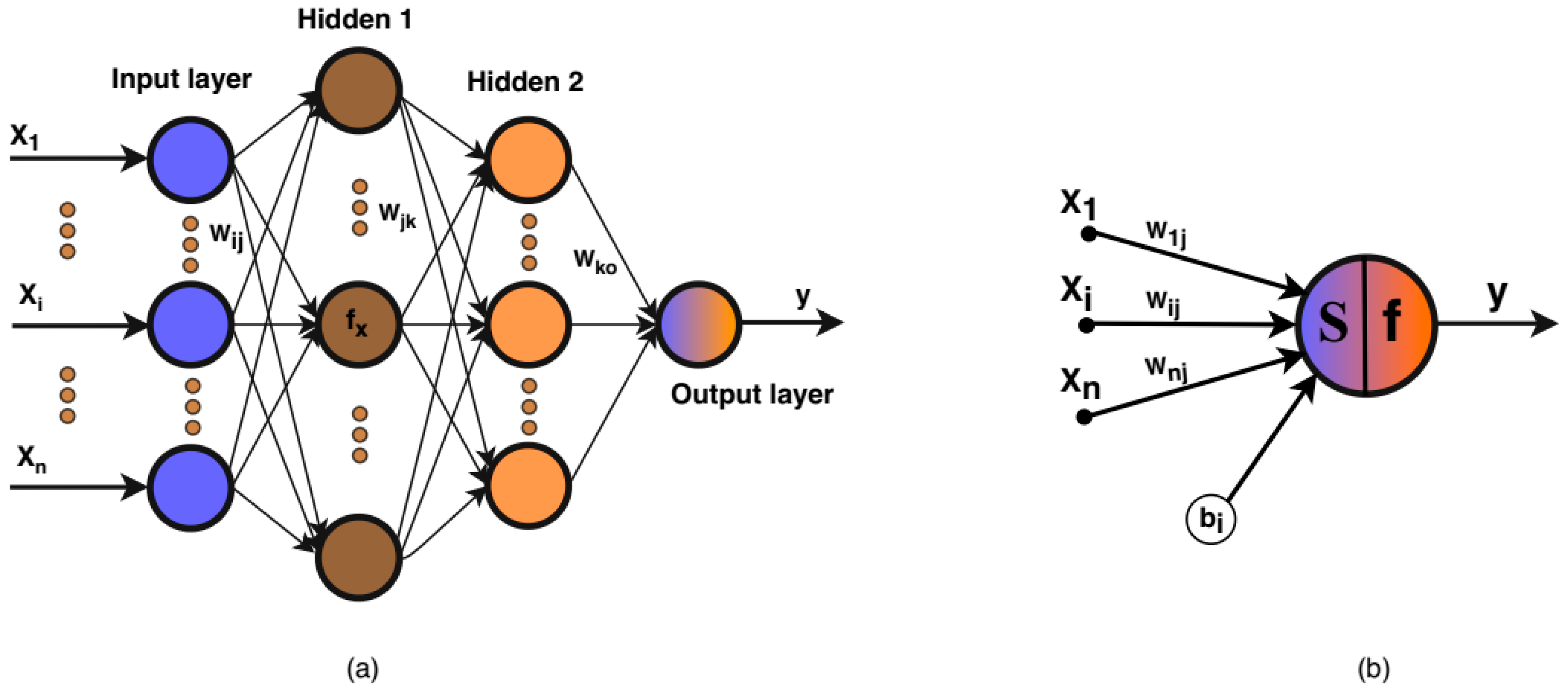
2.2.1. Neural Network Model
2.2.2. Gaussian Process Model
2.2.3. Deep Kernel Learning Model
2.2.4. Model Performance Metrics
3. Results
3.1. Responses of the Ion Selective Electrodes
3.2. Determination of the DKL Architecture
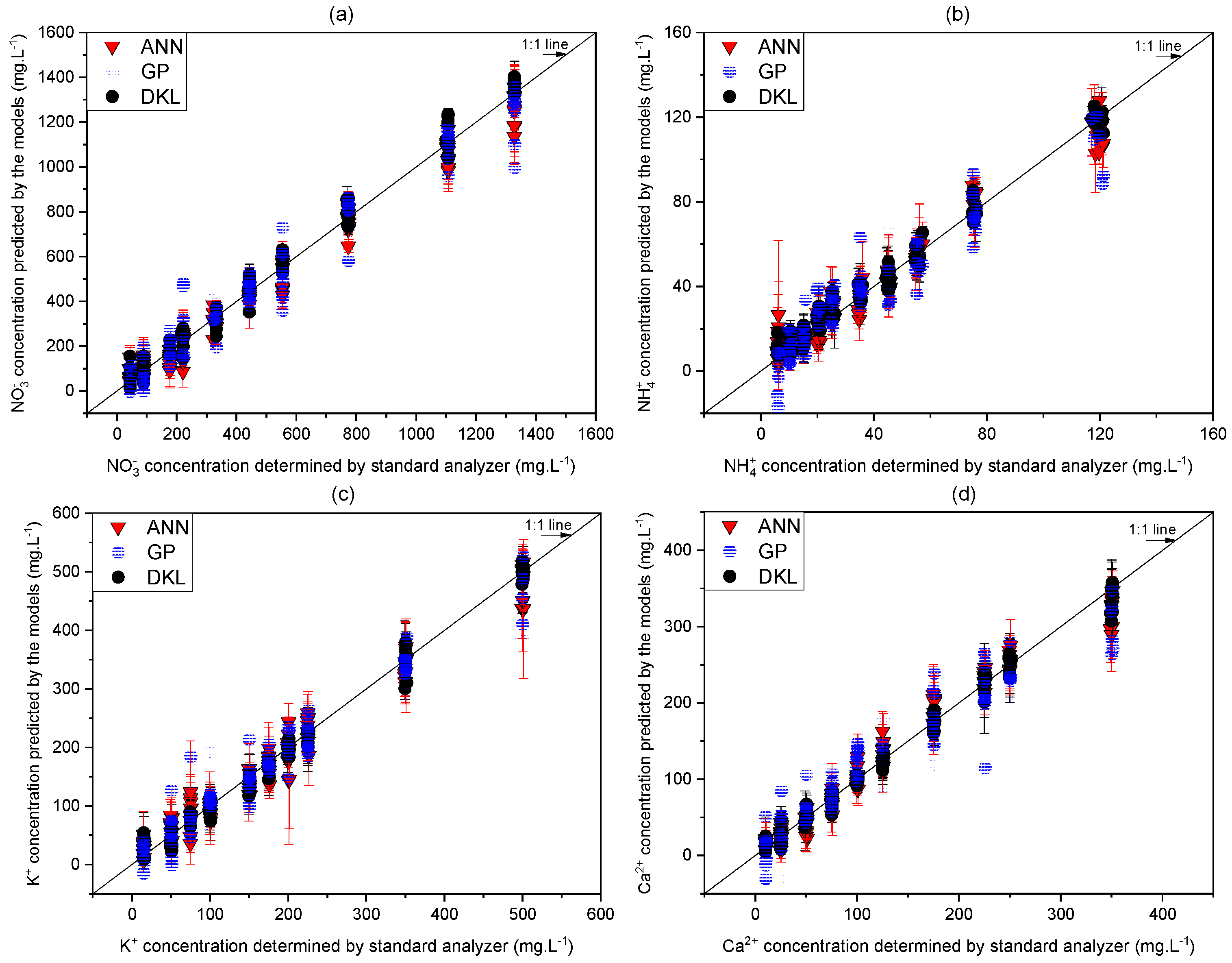
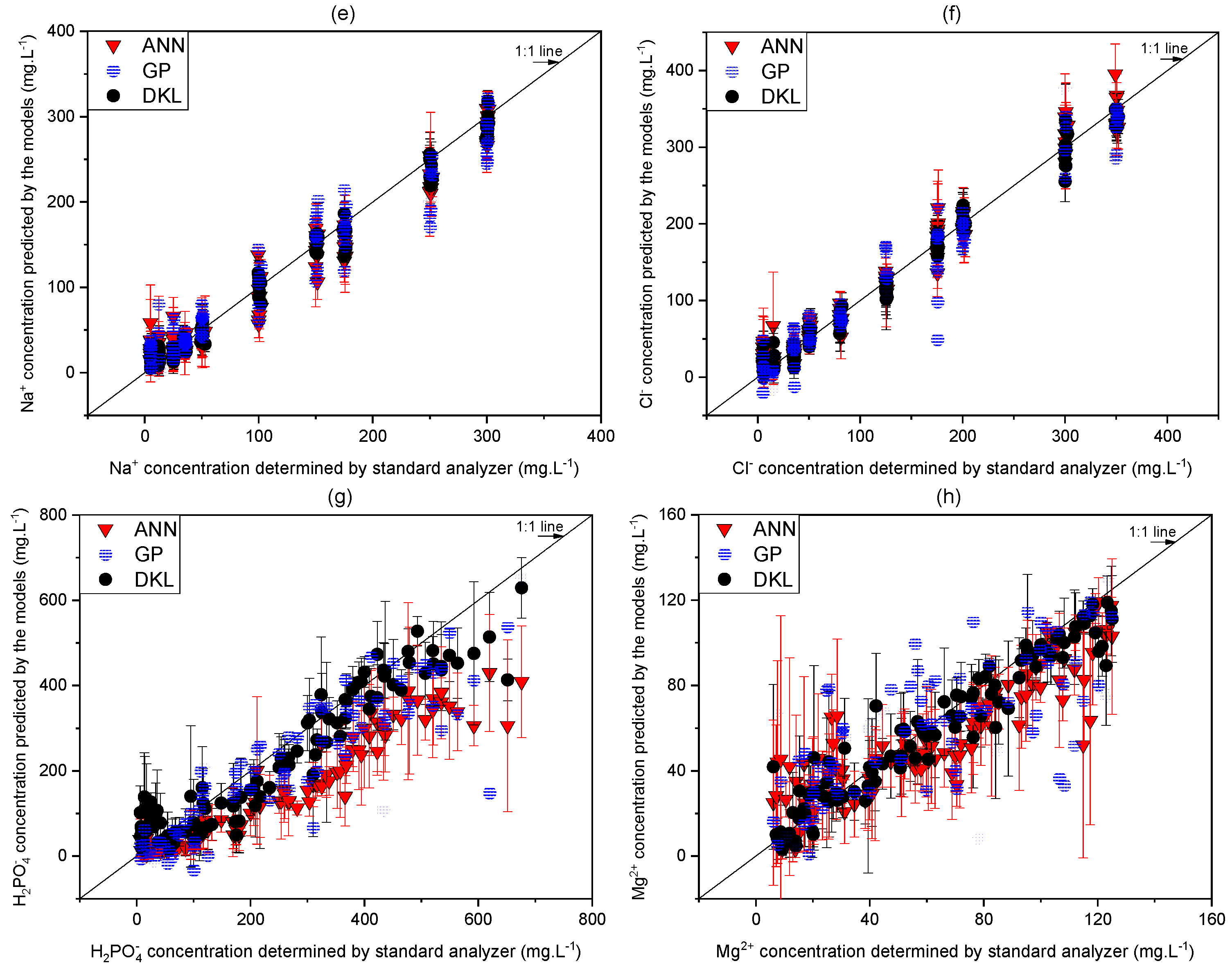
3.3. Evaluation of the Performance of Proposed Models
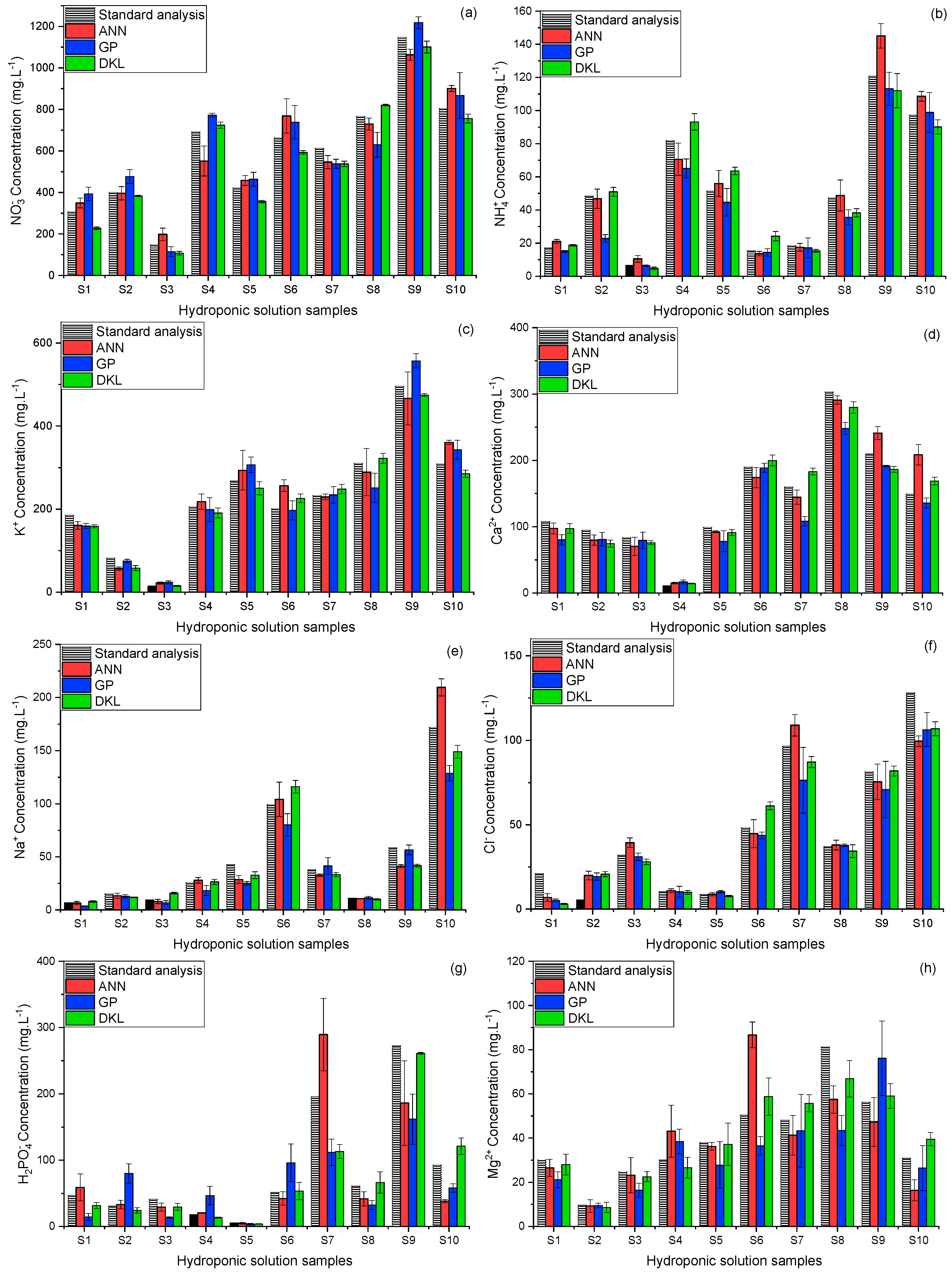
3.4. Validation of the Proposed Models with Real Hydroponic Samples
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Palermo, M.; Paradiso, R.; De Pascale, S.; Fogliano, V. Hydroponic Cultivation Improves the Nutritional Quality of Soybean and Its Products. J. Agric. Food Chem. 2012, 60, 250–255. [Google Scholar] [CrossRef]
- Despommier, D. The Vertical Farm: Feeding the World in the 21st Century; Macmillan: New York, NY, USA, 2010. [Google Scholar]
- Jones, J.B., Jr. Complete Guide for Growing Plants Hydroponically; CRC Press: New York, NY, USA, 2014. [Google Scholar]
- Hosseinzadeh, S.; Verheust, Y.; Bonarrigo, G.; Van Hulle, S. Closed hydroponic systems: Operational parameters, root exudates occurrence and related water treatment. Rev. Environ. Sci. Bio-Technol. 2017, 16, 59–79. [Google Scholar] [CrossRef]
- Bamsey, M.; Graham, T.; Thompson, C.; Berinstain, A.; Scott, A.; Dixon, M. Ion-specific nutrient management in closed systems: The necessity for ion-selective sensors in terrestrial and space-based agriculture and water management systems. Sensors 2012, 12, 13349–13392. [Google Scholar] [CrossRef]
- Rius-Ruiz, F.X.; Andrade, F.J.; Riu, J.; Rius, F.X. Computer-operated analytical platform for the determination of nutrients in hydroponic systems. Food Chem. 2014, 147, 92–97. [Google Scholar] [CrossRef] [PubMed]
- Kim, H.-J.; Kim, D.-W.; Kim, W.K.; Cho, W.-J.; Kang, C.I. PVC membrane-based portable ion analyzer for hydroponic and water monitoring. Comput. Electron. Agric. 2017, 140, 374–385. [Google Scholar] [CrossRef]
- Kim, H.-J.; Hummel, J.W.; Sudduth, K.A.; Motavalli, P.P. Simultaneous Analysis of Soil Macronutrients Using Ion-Selective Electrodes. Soil Sci. Soc. Am. J. 2007, 71, 1867. [Google Scholar] [CrossRef] [Green Version]
- Rundle, C.C. A Beginners Guide To Ion-Selective Electrode Measurements. 2000. Available online: http://www.nico2000.net/Book/Guide1.html (accessed on 14 September 2013).
- Lindner, E.; Pendley, B.D. A tutorial on the application of ion-selective electrode potentiometry: An analytical method with unique qualities, unexplored opportunities and potential pitfalls; Tutorial. Anal. Chim. Acta 2013, 762, 1–13. [Google Scholar] [CrossRef]
- Bratov, A.; Abramova, N.; Ipatov, A. Recent trends in potentiometric sensor arrays—A review. Anal. Chim. Acta 2010, 678, 149–159. [Google Scholar] [CrossRef]
- Codinachs, L.M.; Baldi, A.; Merlos, A.; Abramova, N.; Ipatov, A.; Jimenez-Jorquera, C.; Bratov, A. Integrated multisensor for FIA-based electronic tongue applications. IEEE Sens. J. 2008, 8, 608–615. [Google Scholar] [CrossRef]
- Gutiérrez, M.; Moo, V.M.; Alegret, S.; Leija, L.; Hernández, P.R.; Muñoz, R.; del Valle, M. Electronic tongue for the determination of alkaline ions using a screen-printed potentiometric sensor array. Microchim. Acta 2008, 163, 81–88. [Google Scholar] [CrossRef]
- Jung, D.H.; Kim, H.J.; Choi, G.L.; Ahn, T.I.; Son, J.E.; Sudduth, K.A. Automated Lettuce Nutrient Solution Management Using An Array of Ion-Selective Electrodes. Trans. Asabe 2015, 58, 1309–1319. [Google Scholar]
- Cho, W.J.; Kim, H.J.; Jung, D.H.; Kim, D.W.; Ahn, T.I.; Son, J.E. On-site ion monitoring system for precision hydroponic nutrient management. Comput. Electron. Agric. 2018, 146, 51–58. [Google Scholar] [CrossRef]
- Wang, L.; Cheng, Y.; Lamb, D.; Lesniewski, P.J.; Chen, Z.L.; Megharaj, M.; Naidu, R. Novel recalibration methodologies for ion-selective electrode arrays in the multi-ion interference scenario. J. Chemom. 2017, 31. [Google Scholar] [CrossRef]
- Mueller, A.V.; Hemond, H.F. Statistical generation of training sets for measuring NO3−, NH4+ and major ions in natural waters using an ion selective electrode array. Environ. Sci. Process. Impacts 2016, 18, 590–599. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, L.; Yang, D.; Fang, C.; Chen, Z.L.; Lesniewski, P.J.; Mallavarapu, M.; Naidu, R. Application of neural networks with novel independent component analysis methodologies to a Prussian blue modified glassy carbon electrode array. Talanta 2015, 131, 395–403. [Google Scholar] [CrossRef] [PubMed]
- Gutiérrez, M.; Alegret, S.; Cáceres, R.; Casadesús, J.; Marfà, O.; del Valle, M. Application of a potentiometric electronic tongue to fertigation strategy in greenhouse cultivation. Comput. Electron. Agric. 2007, 57, 12–22. [Google Scholar] [CrossRef]
- Mueller, A.V.; Hemond, H.F. Extended artificial neural networks: Incorporation of a priori chemical knowledge enables use of ion selective electrodes for in-situ measurement of ions at environmentally relevant levels. Talanta 2013, 117, 112–118. [Google Scholar] [CrossRef]
- Cuartero, M.; Ruiz, A.; Oliva, D.J.; Ortuño, J.A. Multianalyte detection using potentiometric ionophore-based ion-selective electrodes. Sens. Actuators B Chem. 2017, 243, 144–151. [Google Scholar] [CrossRef]
- Duarte, L.T.; Jutten, C. Design of Smart Ion-Selective Electrode Arrays Based on Source Separation through Nonlinear Independent Component Analysis. Oil Gas Sci. Technol.-Rev. D Ifp Energ. Nouv. 2014, 69, 293–306. [Google Scholar] [CrossRef] [Green Version]
- Duarte, L.T.; Suyama, R.; Attux, R.; Romano, J.M.T.; Jutten, C. A novel blind source separation method based on monotonic functions and its application to ion-selective electrode arrays. In Proceedings of the 2017 ISOCS/IEEE International Symposium on Olfaction and Electronic Nose (ISOEN), Montreal, QC, Canada, 28–31 May 2017. [Google Scholar]
- Wang, L.; Yang, D.; Chen, Z.L.; Lesniewski, P.J.; Naidu, R. Application of neural networks with novel independent component analysis methodologies for the simultaneous determination of cadmium, copper, and lead using an ISE array. J. Chemom. 2014, 28, 491–498. [Google Scholar] [CrossRef]
- Magalhaes, J.; Machado, A. Array of potentiometric sensors for the analysis of creatinine in urine samples. Analyst 2002, 127, 1069–1075. [Google Scholar] [CrossRef] [PubMed]
- Rudnitskaya, A.; Costa, A.M.S.; Delgadillo, I. Calibration update strategies for an array of potentiometric chemical sensors. Sens. Actuators B Chem. 2017, 238, 1181–1189. [Google Scholar] [CrossRef]
- Chen, F.; Wei, D.; Tang, Y. Virtual Ion Selective Electrode for Online Measurement of Nutrient Solution Components. IEEE Sens. J. 2011, 11, 462–468. [Google Scholar] [CrossRef]
- Jung, D.-H.; Kim, H.-J.; Kim, H.S.; Choi, J.; Kim, J.D.; Park, S.H. Fusion of Spectroscopy and Cobalt Electrochemistry Data for Estimating Phosphate Concentration in Hydroponic Solution. Sensors 2019, 19, 2596. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tuan, V.N.; Dinh, T.D.; Khattak, A.M.; Zheng, L.; Chu, X.; Gao, W.; Wang, M. Multivariate Standard Addition Cobalt Electrochemistry Data Fusion for Determining Phosphate Concentration in Hydroponic Solution. IEEE Access 2020, 8, 28289–28300. [Google Scholar] [CrossRef]
- Cho, W.J.; Kim, H.J.; Jung, D.H.; Han, H.J.; Cho, Y.Y. Hybrid Signal-Processing Method Based on Neural Network for Prediction of NO3, K, Ca, and Mg Ions in Hydroponic Solutions Using an Array of Ion-Selective Electrodes. Sensors 2019, 19, 5508. [Google Scholar] [CrossRef] [Green Version]
- Sales, F.; Callao, M.P.; Rius, F.X. Multivariate standardization for correcting the ionic strength variation on potentiometric sensor arrays. Analyst 2000, 125, 883–888. [Google Scholar] [CrossRef]
- Jones, J.B., Jr. Hydroponics: A Practical Guide for the Soilless Grower; CRC Press Inc.: Boca Raton, FL, USA, 2005. [Google Scholar]
- Yu, C.; Seslija, M.; Brownbridge, G.; Mosbach, S.; Kraft, M.; Parsi, M.; Davis, M.; Page, V.; Bhave, A. Deep Kernel Learning Approach to Engine Emissions Modelling. Data-Cent. Eng. 2020. [Google Scholar] [CrossRef]
- Alsaedi, B.S.O.; McGraw, C.M.; Schaerf, T.M.; Dillingham, P.W. Multivariate limit of detection for non-linear sensor arrays. Chemom. Intell. Lab. Syst. 2020, 201, 104016. [Google Scholar] [CrossRef]
- Wilson, A.G.; Hu, Z.T.; Salakhutdinov, R.; Xing, E.P. Deep kernel learning. In Artificial Intelligence and Statistics; Gretton, A., Robert, C.C., Eds.; Microtome Publishing: Brookline, MA, USA, 2016; Volume 51, pp. 370–378. [Google Scholar]
- Jiu, M.; Sahbi, H. Nonlinear deep kernel learning for image annotation. IEEE Trans. Image Process. 2017, 26, 1820–1832. [Google Scholar] [CrossRef]
- Zheng, S.H.; Liu, K.X.; Xu, Y.L.; Chen, H.; Zhang, X.L.; Liu, Y. Robust Soft Sensor with Deep Kernel Learning for Quality Prediction in Rubber Mixing Processes. Sensors 2020, 20, 695. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Conagin, A.; Barbin, D.; Zocchi, S.S.; Demétrio, C.G.B. Fractional factorial designs for fertilizer experiments with 25 treatments in poor soils. Rev. Bras. Biom. 2014, 32, 180–189. [Google Scholar]
- Trejo-Téllez, L.I.; Gómez-Merino, F.C. Nutrient solutions for hydroponic systems. In Hydroponics-A Standard Methodology for Plant Biological Researches; InTech: Rijeka, Croatia, 2012. [Google Scholar]
- Puri, M.; Pathak, Y.; Sutariya, V.K.; Tipparaju, S.; Moreno, W. Artificial Neural Network for Drug Design, Delivery and Disposition; Academic Press: San Diego, CA, USA, 2015. [Google Scholar]
- Basheer, I.A.; Hajmeer, M. Artificial neural networks: Fundamentals, computing, design, and application. J. Microbiol. Methods 2000, 43, 3–31. [Google Scholar] [CrossRef]
- Rasmussen, C.; Williams, C. Gaussian Processes for Machine Learning the MIT Press; MIT: Cambridge, MA, USA, 2006. [Google Scholar]
- Neal, R.M. Bayesian Learning for Neural Networks; Springer Science & Business Media: New York, NY, USA, 2012; Volume 118. [Google Scholar]
- Wilson, A.; Adams, R. Gaussian process kernels for pattern discovery and extrapolation. In Proceedings of the International Conference on Machine Learning, Atlanta, GA, USA, 13 February 2013; pp. 1067–1075. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Horvai, G.; Tóth, K.; Pungor, E. A simple continuous method for calibration and measurement with ion-selective electrodes. Anal. Chim. Acta 1976, 82, 45–54. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Wang, L.; Cheng, Y.; Lamb, D.; Chen, Z.; Lesniewski, P.J.; Megharaj, M.; Naidu, R. Simultaneously determining multi-metal ions using an ion selective electrode array system. Environ. Technol. Innov. 2016, 6, 165–176. [Google Scholar] [CrossRef]
- Morf, W.E. The Principles of Ion-Selective Electrodes and of Membrane Transport; Elsevier: New York, NY, USA, 2012. [Google Scholar]
- Baret, M.; Massart, D.; Fabry, P.; Conesa, F.; Eichner, C.; Menardo, C. Application of neural network calibrations to an halide ISE array. Talanta 2000, 51, 863–877. [Google Scholar] [CrossRef]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: New York, NY, USA, 2006. [Google Scholar]
- Dimeski, G.; Badrick, T.; St John, A. Ion Selective Electrodes (ISEs) and interferences-A review. Clin. Chim. Acta 2010, 411, 309–317. [Google Scholar] [CrossRef]
- Mohammed, R.O.; Cawley, G.C. Over-fitting in model selection with Gaussian process regression. In Proceedings of the International Conference on Machine Learning and Data Mining in Pattern Recognition, New York, NY, USA, 15–20 July 2017; pp. 192–205. [Google Scholar]
- Cortina, M.; Duran, A.; Alegret, S.; del Valle, M. A sequential injection electronic tongue employing the transient response from potentiometric sensors for anion multidetermination. Anal. Bioanal. Chem. 2006, 385, 1186–1194. [Google Scholar] [CrossRef]
- Zhang, Y.; Ling, C. A strategy to apply machine learning to small datasets in materials science. NPJ Comput. Mater. 2018, 4, 1–8. [Google Scholar] [CrossRef] [Green Version]
- Álvarez, M.A.; Lawrence, N.D. Computationally efficient convolved multiple output Gaussian processes. J. Mach. Learn. Res. 2011, 12, 1459–1500. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sensor | Measurement Range | Membrane Type | Response Time (s) | Manufacturer |
|---|---|---|---|---|
| Nitrate ISE: REX972123 | 0.6–60000 | PVC | ~50 | Shanghai INESA, China |
| Ammonium ISE: REX 972,122 | 0.02–14000 | PVC | ~50 | Shanghai INESA, China |
| Potassium ISE: Orion 9719BNWP | 0.04–39000 | PVC | ~50 | Thermo Fisher, USA |
| Calcium ISE: Orion 9720BNWP | 0.02–40000 | PVC | ~50 | Thermo Fisher, USA |
| Sodium ISE: pNa 701 | 0.03–23000 | Glass | ~50 | Shanghai INESA, China |
| Chloride ISE: pCl 202 | 0.35–3500 | PVC | ~50 | Shanghai INESA, China |
| pH electrode: E-201F | 2–14 | - | ~50 | Shanghai INESA, China |
| EC electrode: DJS-1C | 0–10000 | - | - | Shanghai INESA, China |
| Temperature probe: Pt100 | 0–100 | - | - | Yuace, China |
| Ions | Level 1 | Level 2 | Level 3 | Level 4 | Level 5 | Level 6 | Level 7 | Level 8 | Level 9 | Level 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| Nitrate () | 44 | 88 | 177 | 221 | 332 | 442 | 553 | 769 | 1106 | 1328 |
| Ammonium () | 6 | 10 | 15 | 20 | 25 | 35 | 45 | 55 | 75 | 120 |
| Potassium () | 15 | 50 | 75 | 100 | 150 | 175 | 200 | 225 | 350 | 500 |
| Calcium () | 10 | 25 | 50 | 75 | 100 | 125 | 175 | 225 | 250 | 350 |
| Sodium () | 5 | 12 | 25 | 35 | 50 | 100 | 150 | 175 | 250 | 300 |
| Chloride () | 5 | 15 | 35 | 50 | 80 | 125 | 175 | 200 | 300 | 350 |
| Sample | Grown Plant | Growing Period | Nutrient Standard | Sampling Sites |
|---|---|---|---|---|
| S1 | Lettuce 1 | Three weeks | Hoagland’s solution | Experimental Plant Factory, CIEE, CAU |
| S2 | Perilla | Five weeks | Hoagland’s solution | Experimental Plant Factory, CIEE, CAU |
| S3 | Lettuce 2 | Four weeks | Hoagland’s solution | Experimental Plant Factory, CIEE, CAU |
| S4 | Purple bok choy | Five weeks | Hoagland’s solution | Experimental Plant Factory, CIEE, CAU |
| S5 | Chinese cabbage | Six weeks | Yamazaki’s solution | Experimental Plant Factory, CIEE, CAU |
| S6 | Strawberry | Eight weeks | Hoagland’s solution | Experimental Plant Factory, CIEE, CAU |
| S7 | Gynura bicolor DC | Five weeks | Hoagland’s solution | Experimental Plant Factory, CIEE, CAU |
| S8 | Amaranth | Four weeks | Yamazaki’s solution | Experimental farm, CIEE, CAU |
| S9 | Eggplant | Twelve weeks | Yamazaki’s solution | Experimental farm, CIEE, CAU |
| S10 | Tomato | Six weeks | Yamazaki’s solution | Experimental farm, CIEE, CAU |
| Parameters | Values |
| Number of hidden layers | 1, 2, 3, 4, 5, 6 |
| Hidden layer size | 1 to 1000 |
| Hidden layer transfer function f(x) | tansig, logsig, linear, ReLU |
| Output layer transfer function | ReLU |
| Optimization algorithm | Stochastic gradient descent (SGD), Broyden–Fletcher–Goldfarb–Shanno (BFGS), Adam |
| Dropout rate | 0.5 to 0.99 |
| Learning rate | 0.001 to 0.1 |
| Max number of epochs | 1000 |
| Prior whitenoise level | 0.001 to 1 |
| Kernel | Radial basic function (RBF), Dotproduct, Spectral mixture (SM) |
| Training goal | 10−6 |
| ISEs | DCM | MSAM | ||
|---|---|---|---|---|
| Calibrating Equation | Calibrating Equation | |||
| Nitrate | 0.93 | y = −22.04ln(x) + 202.62 | 0.95 | y = −22.86ln(x) + 208.47 |
| Ammonium | 0.90 | y = 22.856ln(x) − 255.01 | 0.92 | y = 22.92ln(x) − 253.87 |
| Potassium | 0.95 | y = 23.39ln(x) − 240.07 | 0.97 | y = 23.07ln(x) − 237.03 |
| Calcium | 0.94 | y = 11.419ln(x) − 79.31 | 0.96 | y = 11.06ln(x) − 76.90 |
| Sodium | 0.91 | y = 18.227ln(x) − 178.31 | 0.93 | y = 19.76ln(x) − 186.22 |
| Chloride | 0.94 | y = −23.28ln(x) + 186.54 | 0.96 | y = −23.02ln(x) + 192.33 |
| Layer 1 | Layer 2 | Layer 3 | Layer 4 | Layer 5 | Opt | LR | N.o.E | KF | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| N.o.N | AF | DR | N.o.N | AF | DR | N.o.N | AF | DR | N.o.N | AF | DR | N.o.N | AF | DR | Adam | 0.005 | 250 | RBF |
| 580 | Tanh | 0.99 | 580 | Tanh | 0.99 | 100 | ReLU | 0.99 | 100 | ReLU | 0.99 | 8 | ReLU | 0.99 | ||||
| Species | Models | Predicting Equation | RMSE | Coefficient of Performance () |
|---|---|---|---|---|
| Nitrate | ANN | y = 0.95x + 18.11 | 91.5 | 0.95 |
| GP | y = 0.94x − 10.93 | 102.7 | 0.94 | |
| DKL | y = 1.01x + 17.81 | 58.5 | 0.98 | |
| Ammonium | ANN | y = 0.92x + 4.54 | 10.9 | 0.92 |
| GP | y = 0.90x + 3.80 | 13.1 | 0.90 | |
| DKL | y = 0.95x + 5.13 | 7.4 | 0.95 | |
| Potassium | ANN | y = 0.94x + 7.33 | 33.5 | 0.95 |
| GP | y = 0.95x + 11.50 | 31.2 | 0.96 | |
| DKL | y = 0.99x + 5.59 | 25.2 | 0.978 | |
| Calcium | ANN | y = 0.98x + 4.20 | 23.6 | 0.96 |
| GP | y = 0.85x + 22.30 | 35.3 | 0.92 | |
| DKL | y = 0.99x + 5.27 | 18.8 | 0.97 | |
| Sodium | ANN | y = 0.94x − 1.97 | 22.5 | 0.94 |
| GP | y = 0.86x + 14.11 | 29.3 | 0.92 | |
| DKL | y = 0.97x + 1.08 | 18.9 | 0.96 | |
| Chloride | ANN | y = 0.97x + 1.22 | 25.0 | 0.95 |
| GP | y = 0.95x + 5.67 | 27.2 | 0.94 | |
| DKL | y = 0.99x + 2.68 | 20.3 | 0.97 | |
| Phosphate | ANN | y = 0.71x + 31.59 | 122.5 | 0.76 |
| GP | y = 0.62x + 20.27 | 135.8 | 0.61 | |
| DKL | y = 0.85x + 17.82 | 76.2 | 0.86 | |
| Magnesium | ANN | y = 0.82x + 11.43 | 21.3 | 0.75 |
| GP | y = 0.63x + 10.64 | 25.2 | 0.62 | |
| DKL | y = 0.88x + 2.11 | 13.1 | 0.89 |
| Considered Ions | Range of Concentration ) | Models | Accuracy (RMSE, ) | Precision (CV, %) |
|---|---|---|---|---|
| Nitrate | 150–1150 | ANN | 83.8 | 7.2 |
| GP | 86.1 | 8.4 | ||
| DKL | 63.8 | 3.5 | ||
| Ammonium | 6–120 | ANN | 10.3 | 9.2 |
| GP | 12.2 | 10.3 | ||
| DKL | 8.3 | 7.0 | ||
| Potassium | 15–500 | ANN | 36.3 | 9.2 |
| GP | 35.2 | 8.8 | ||
| DKL | 29.2 | 5.4 | ||
| Calcium | 10–305 | ANN | 25.2 | 7.7 |
| GP | 29.1 | 9.6 | ||
| DKL | 18.5 | 5.5 | ||
| Sodium | 6–175 | ANN | 14.8 | 9.2 |
| GP | 17.1 | 9.9 | ||
| DKL | 11.8 | 6.8 | ||
| Chloride | 1.6–128 | ANN | 11.7 | 9.5 |
| GP | 12.8 | 10.5 | ||
| DKL | 8.8 | 6.9 | ||
| Phosphate | 5–275 | ANN | 50.5 | 22.3 |
| GP | 55.8 | 23.6 | ||
| DKL | 29.6 | 13.9 | ||
| Magnesium | 10–80 | ANN | 16.9 | 21.3 |
| GP | 18.1 | 23.5 | ||
| DKL | 8.7 | 14.8 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tuan, V.N.; Khattak, A.M.; Zhu, H.; Gao, W.; Wang, M. Combination of Multivariate Standard Addition Technique and Deep Kernel Learning Model for Determining Multi-Ion in Hydroponic Nutrient Solution. Sensors 2020, 20, 5314. https://doi.org/10.3390/s20185314
Tuan VN, Khattak AM, Zhu H, Gao W, Wang M. Combination of Multivariate Standard Addition Technique and Deep Kernel Learning Model for Determining Multi-Ion in Hydroponic Nutrient Solution. Sensors. 2020; 20(18):5314. https://doi.org/10.3390/s20185314
Chicago/Turabian StyleTuan, Vu Ngoc, Abdul Mateen Khattak, Hui Zhu, Wanlin Gao, and Minjuan Wang. 2020. "Combination of Multivariate Standard Addition Technique and Deep Kernel Learning Model for Determining Multi-Ion in Hydroponic Nutrient Solution" Sensors 20, no. 18: 5314. https://doi.org/10.3390/s20185314