
Two Ways to Plan Your Study
When you want to compare several user interfaces in a single study, there are two ways of planning your study:
- Between-subjects (or between-groups) study design: different people test each condition, so that each person is only exposed to a single user interface .
- Within-subjects (or repeated-measures) study design: the same person tests all the conditions (i.e., all the user interfaces).
(Note that here we use the word “design” to refer to the design of the study, and not to website design. The design of the study is also called experimental design.)
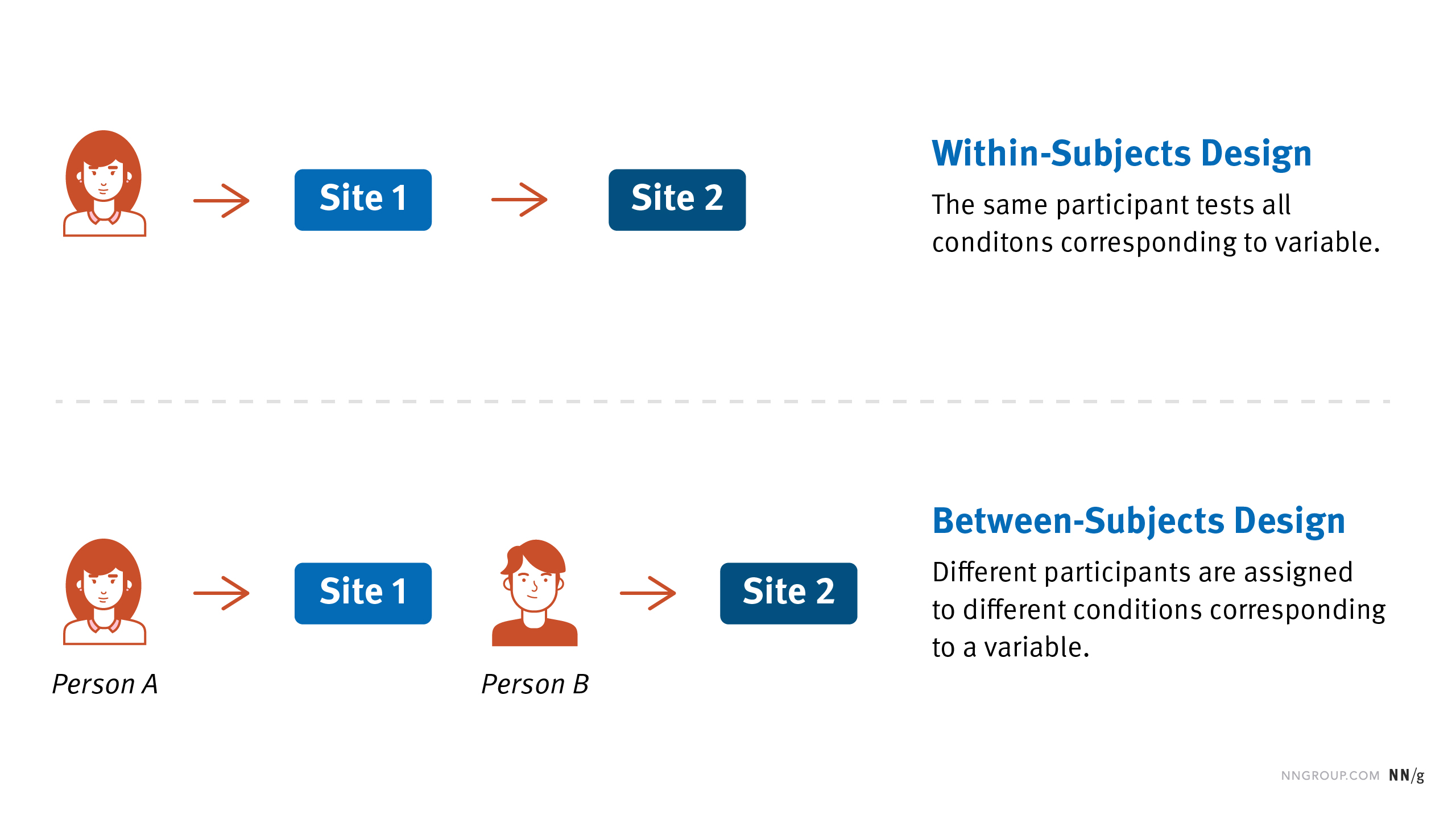
For example, if we wanted to compare two car-rental sites A and B by looking at how participants book cars on each site, our study could be designed in two different ways:
- Between-subjects: Each participant could test a single car-rental site and book a car only on that site.
- Within-subjects: Each participant could test both car-rental sites and book a car on each.
Any type of user research that involves more than a single test condition must determine whether to be between-subjects or within-subjects. However, the distinction is particularly important for quantitative studies.
Experimental Design in Quantitative Studies
Unlike qualitative studies, quantitative usability studies aim to result in findings that are statistically likely to generalize to the whole user population. How the data from quantitative studies is analyzed depends on the study design.
Independent and Dependent Variables
Often, the main goal of quantitative usability studies is to compare — a site with its competitors, two different iterations of a design, or two different groups of users (such as experts vs. novices). Like in any scientific experiment in which we want to detect causal relationships, a quantitative study involves two types of variables:
- Independent variables, which are directly manipulated by the researcher
- Dependent variables, which are measured (and expected to vary as a result of the independent-variable manipulation)
(If the study produces statistically significant results, then we can say that a change in the independent variable caused a change in the dependent variable.)
Let’s go back to our original car-rental example. If we wanted to measure which of the two sites, A or B, is better for the task of reserving a car, we could choose Site (with two possible values or levels — A and B) as the independent variable, and the time on task and the accuracy for booking a car could be the dependent variables. The goal of the study would be to see whether the dependent variables (time and accuracy) change when we vary the site or they stay the same. (If they stay the same, then none of the sites is better than the other.)
Between-Subjects, Within-Subjects, or Both?
To plan our study, the next question is whether the study design should be between-subjects or within-subjects — that is, whether a participant in the study should be exposed to all the different conditions for the independent variable in our study (within-subjects) or only to one condition (between-subjects). The choice of experimental design will affect the type of statistical analysis that should be used on your data.
A study design can be both within-subjects and between-subjects. For example, assume that, in the case of our car-rental study, we were also interested in knowing how participants younger than 30 perform compared with older participants. In this case we would have two independent variables:
- Age, with 2 levels: under 30, over 30
- Site, with 2 levels: A and B
For the study, we will recruit an equal number of participants in each age group. Let’s assume that we decide that each participant, whether under or over 30, will make a car-rental reservation both on site A and on site B. In this case, the study is within-subjects with respect to the independent variable Site (because each person sees both levels of this variable — that is, both site A and site B). However, the study is between-subjects with respect to Age: one person can only be in a single age group (either under or over 30, not both). (Well, technically, you could pick a group of under-30-year olds and wait until they turn 30 to have them test the sites again, but this setup is obviously highly impractical.)
Some independent variables may impose the choice of study design. Age is one of them, as seen above. Others are Expertise (if we want to compare experts and novices), User Type (if we want to compare different user groups or personas — for example, business traveler vs. leisure traveler), or Gender (assuming that a person cannot be of several genders at the same time). Outside usability, drug trials are one common case of between-subject design: participants are exposed to only one treatment: either the drug being tested or a placebo, not both.
Sometimes the manipulation changes the state of the participant: for example, if you want to see which of two curricula is more effective for teaching reading, you could not have the same student be exposed to both, because once she’s learned how to read, she cannot unlearn it.
Which Is Better: Between-Subjects or Within-Subjects?
Unfortunately, there is no easy answer to this question. As seen above, sometimes your independent variables will dictate the experimental design. But in many situations, both designs may be possible. The table below summarizes the advantages of both.
|
Between-Subjects: Pros |
Within-Subjects: Pros |
|---|---|
|
No transfer across conditions |
Require fewer participants and are cheaper |
|
Shorter study sessions |
Minimize the noise in your data |
|
Easy to set up, especially when you have multiple independent variables |
|
Below we discuss each of these advantages.
Between-Subjects Minimizes the Learning and Transfer Across Conditions
After a person has completed a series of tasks on a car-rental site, they are more knowledgeable about the domain than she was before. For example, they may now know that car-rental sites charge an extra fee for drivers under 21, or what a collision-damage waiver is. That knowledge will likely help them become more efficient on a second car-rental site, even though that second site may be very different from the first.
With between-subject design, this transfer of knowledge is not an issue — participants are never exposed to several levels of the same independent variable.
Between-Subjects Studies Have Shorter Sessions
A participant who tests a single car-rental site will have a shorter session than one who tests two. Shorter sessions are less tiring (or boring) for users and can also be more appropriate for remote unmoderated testing (especially since tools like UserZoom usually require a fairly short session length).
Between-Subject Studies Are Easier to Set Up
When the study is within-subjects, you will have to use randomization of your stimuli to make sure that there are no order effects.
For example, in our car-rental study, we need to make sure that participants don’t always start with site A and then move on to site B. The order of the sites needs to be random for each participant. This is easy with just two sites: randomly assign 50% of users to start with each site. But let’s say that you want to look at 4 sites and each site could be in dark or light mode. As you increase the number of independent variables and of levels for your independent variables, randomization becomes more difficult to implement within some of the existing platforms for quantitative usability testing.
Within-Subject Designs Require Fewer Participants
To detect a statistically significant difference between two conditions, you’ll often need a fairly large number of a data points (often above 40) in each condition. If you have a within-subject design, each participant will provide a data point for each level of the independent variable. For our car-rental study, 40 participants will provide data points for both sites. But if the study is between-subjects you will need twice as many to get the same number of data points. That means twice the cost. Within-subjects studies are, thus, more cost-effective than between-subjects ones.
Within-Subjects Design Minimize the Noise in Your Data
Perhaps the most important advantage of within-subject designs is that they make it less likely that a real difference that exists between your conditions will stay undetected or be covered by random noise.
Individual participants bring in to the test their own history, background knowledge, and context. One may be tired after a long night of partying, another one may be bored, yet another one may have received a great news just before the study and be happy. If the same participant interacts with all levels of a variable, she will affect them in the same way. The happy person will be happy on both sites, the tired one will be tired on both. But if the study is between-subjects, the happy participant will only interact with one site and may affect the final results. You’ll have to make sure you get a similar happy participant in the other group to counteract her effects.
In practice, researchers won’t be able to assess such differences between participants — although they may match the gender, the experience, and the age across groups, it will be difficult to predict or detect other factors specific to each participant.
Randomization: Essential for Both Types of Design
Whether your experimental design is within-subjects or between-subjects, you will have to be concerned with randomization, although in slightly different ways.
Above, we discussed how randomization counteracts the possible order effects and minimizes transfer and learning across conditions in within-subjects design.
For between-subject designs, you must make sure that participants are allotted randomly to conditions, because you want to ensure that your participant assignment does not affect your study results (that is, it has to ensure that the study has internal validity). Thus, if a researcher decides that all the participants that he likes should interact with site A and then he finds that site A performed better than site B, he won’t know whether he’s discovered a true difference between the sites or whether the result simply reflects his assignment (for example, because people who sense that they are liked tend to return the favor, and may be more patient or have a positive mindset during the test). In this situation, the assignment is a confounding variable.
Even without such an obvious bias as your personal preferences, it’s easy to get randomization wrong. Say that you run a study across four days, Saturday through Tuesday. You might decide to have the first half of the test users start with site A and have the second half of the users start with site B. However, this is not a true randomization, because it’s very likely that certain types of people are more likely to agree to a study during the weekend and other types of people are more likely to sign up for your weekday testing slots. In this example, the day of the week is a confounding variable.
Conclusion
User research can be between-subjects or within-subjects (or both), depending on whether each participant is exposed to only one condition or to all conditions that are varied within a study. Each of these types of experimental design has its own advantages and disadvantages; within-subjects design requires fewer participants and increases the chance of discovering a true difference among your conditions; between-subjects designs minimize the learning effects across conditions, lead to shorter sessions, and may be easier to set up and analyze.


